|
I am a PhD student in the School of Information Science at Japan Advanced Institute of Science and Technology. I work at the Robotics Laboratory and am fortunate to be advised by Prof. Chong Nak Young on 3D Active Semantic SLAM. I obtained my Master degree from the School of Information Science at JAIST, Japan and B.S. degree in Roboitics Engineering from University of Engineering and Technology, Vietnam National University, Vietnam . I worked on real-time semantic-aware simultaneous localization and mapping (SLAM) for Unmanned Aerial Vehicle (UAV). During my Master, I am grateful to collaborate with Prof. Xiem HoangVan, Prof. Armagan Elibol, Prof. Manh Duong Phung and Prof. Van-Truong Nguyen. |

|
|
|
|
I am interested in robotics, machine learning, vision, and control. My work focuses on robots' simultaneous localization and mapping, e.g. probablistic mapping, navigation and exploration, semantic slam, active slam and life-long slam; and of their own dynamics model, e.g. robot dynamics learning, model-based reinforcement learning, and learning from demonstration. I am also interested in modeling uncertainty in map representations and robots' dynamics for safe and active planning and control. |
|
|
|
|
Robotics, Mobile Robotics, Algorithms for Intelligent Robots, Discrete Signal Processing Programming robot with ROS, Robotic Control, Human Machine Interface Mechanical Drawing, Electronics Engineering Practice, PLC and Its Application |
|
|
| Projects for active semantic slam |
|
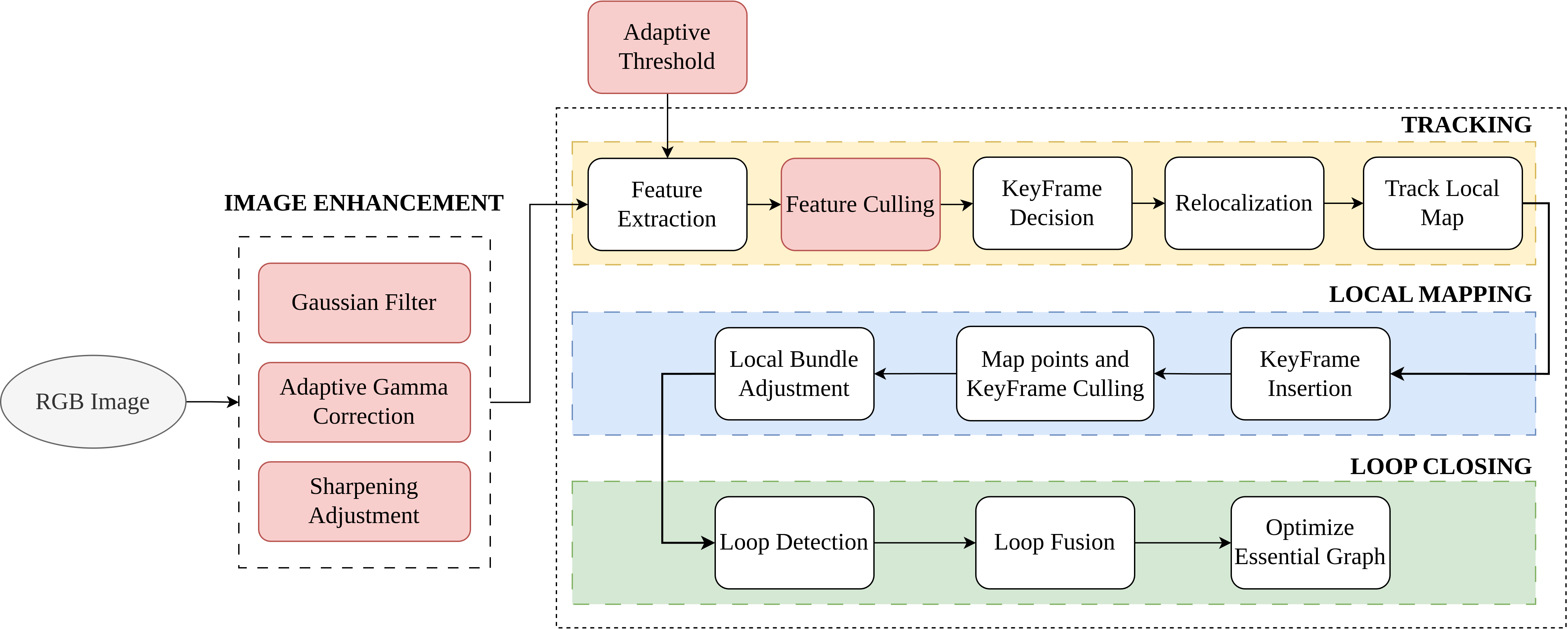
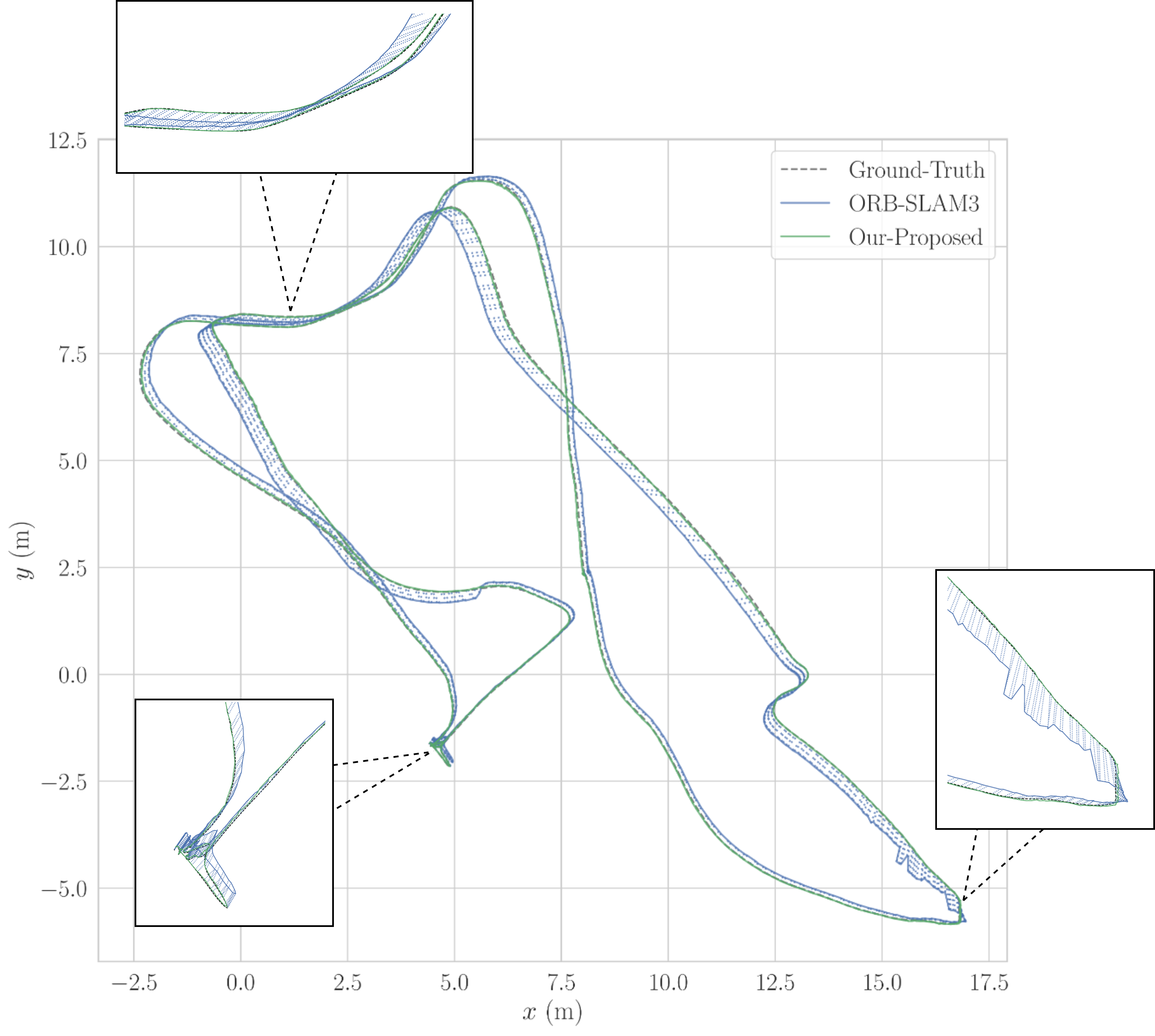
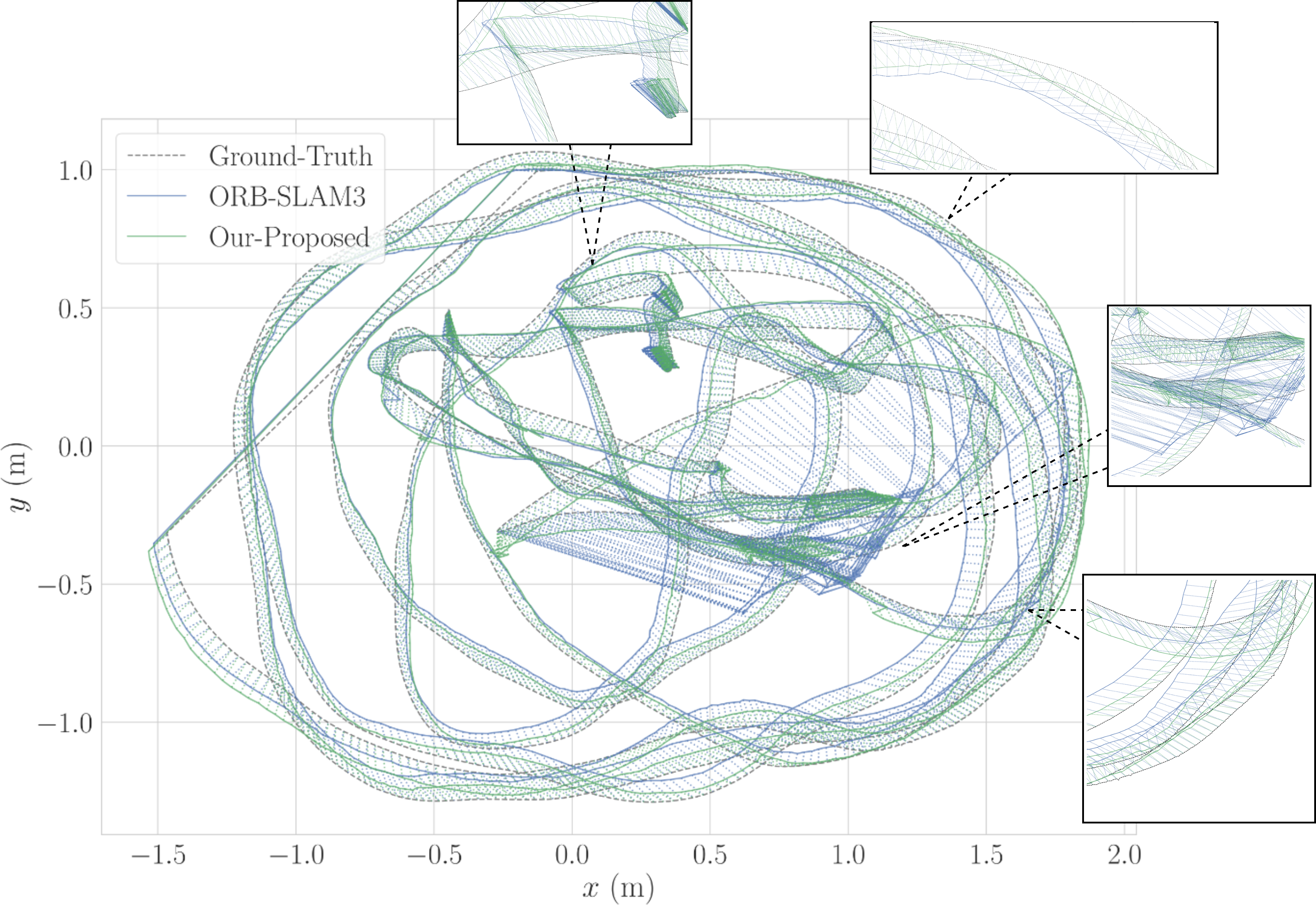
Thanh Nguyen Canh, Bao Nguyen Quoc, HaoLan Zhang, Bupesh Rethinam Veeraiah, Xiem HoangVan Nak Young Chong, Conference version, submitted to ECMR , 2025. website / video / code Robust Visual SLAM (vSLAM) is essential for autonomous systems operating in real-world environments, where challenges such as dynamic objects, low texture, and critically, varying illumination conditions often degrade performance. Existing feature-based SLAM systems rely on fixed front-end parameters, making them vulnerable to sudden lighting changes and unstable feature tracking. To address these challenges, we propose ``IRAF-SLAM'', an Illumination-Robust and Adaptive Feature-Culling front-end designed to enhance vSLAM resilience in complex and challenging environments. Our approach introduces: (1) an image enhancement scheme to preprocess and adjust image quality under varying lighting conditions; (2) an adaptive feature extraction mechanism that dynamically adjusts detection sensitivity based on image entropy, pixel intensity, and gradient analysis; and (3) a feature culling strategy that filters out unreliable feature points using density distribution analysis and a lighting impact factor. Comprehensive evaluations on the TUM and European Robotics Challenge (EuRoC) datasets demonstrate that IRAF-SLAM significantly reduces tracking failures and achieves superior trajectory accuracy compared to state-of-the-art vSLAM methods under adverse illumination conditions. These results highlight the effectiveness of adaptive front-end strategies in improving vSLAM robustness without incurring significant computational overhead. |
|
|
Thanh Nguyen Canh, Van-Truong Nguyen, Xiem HoangVan, Armagan Elibol, Nak Young Chong Conference version, accepted to SII , 2024. website / video / arxiv / code This paper presents a novel approach to address challenges in semantic information extraction and utilization within UAV operations. Our system integrates state-of-the-art visual SLAM to estimate a comprehensive 6-DoF pose and advanced object segmentation methods at the back end. To improve the computational and storage efficiency of the framework, we adopt a streamlined voxel-based 3D map representation - OctoMap to build a working system. Furthermore, the fusion algorithm is incorporated to obtain the semantic information of each frame from the front-end SLAM task, and the corresponding point. By leveraging semantic information, our framework enhances the UAV's ability to perceive and navigate through indoor spaces, addressing challenges in pose estimation accuracy and uncertainty reduction. Through Gazebo simulations, we validate the efficacy of our proposed system and successfully embed our approach into a Jetson Xavier AGX unit for real-world applications. |
|
Thanh Nguyen Canh, Armagan Elibol, Nak Young Chong, Xiem HoangVan Conference version, accepted to ICCAS , 2023. website / video / arxiv / code To autonomously navigate in real-world environments, special in search and rescue operations, Unmanned Aerial Vehicles (UAVs) necessitate comprehensive maps to ensure safety. However, the prevalent metric map often lacks semantic information crucial for holistic scene comprehension. In this paper, we proposed a system to construct a probabilistic metric map enriched with object information extracted from the environment from RGB-D images. Our approach combines a state-of-the-art YOLOv8-based object detection framework at the front end and a 2D SLAM method - CartoGrapher at the back end. To effectively track and position semantic object classes extracted from the front-end interface, we employ the innovative BoT-SORT methodology. A novel association method is introduced to extract the position of objects and then project it with the metric map. Unlike previous research, our approach takes into reliable navigating in the environment with various hollow bottom objects. The output of our system is a probabilistic map, which significantly enhances the map's representation by incorporating object-specific attributes, encompassing class distinctions, accurate positioning, and object heights. A number of experiments have been conducted to evaluate our proposed approach. The results show that the robot can effectively produce augmented semantic maps containing several objects (notably chairs and desks). Furthermore, our system is evaluated within an embedded computer - Jetson Xavier AGX unit to demonstrate the use case in real-world applications. |
|
Thanh Nguyen Canh, Truong Son Nguyen, Cong Hoang Quach, Xiem HoangVan, Manh Duong Phung Conference version, accepted to ICCAS , 2022. website / arxiv In this work, we propose a new approach that combines data from multiple sensors for reliable obstacle avoidance. The sensors include two depth cameras and a LiDAR arranged so that they can capture the whole 3D area in front of the robot and a 2D slide around it. To fuse the data from these sensors, we first use an external camera as a reference to combine data from two depth cameras. A projection technique is then introduced to convert the 3D point cloud data of the cameras to its 2D correspondence. An obstacle avoidance algorithm is then developed based on the dynamic window approach. A number of experiments have been conducted to evaluate our proposed approach. The results show that the robot can effectively avoid static and dynamic obstacles of different shapes and sizes in different environments. |
| Projects for PCB defect detection |
|
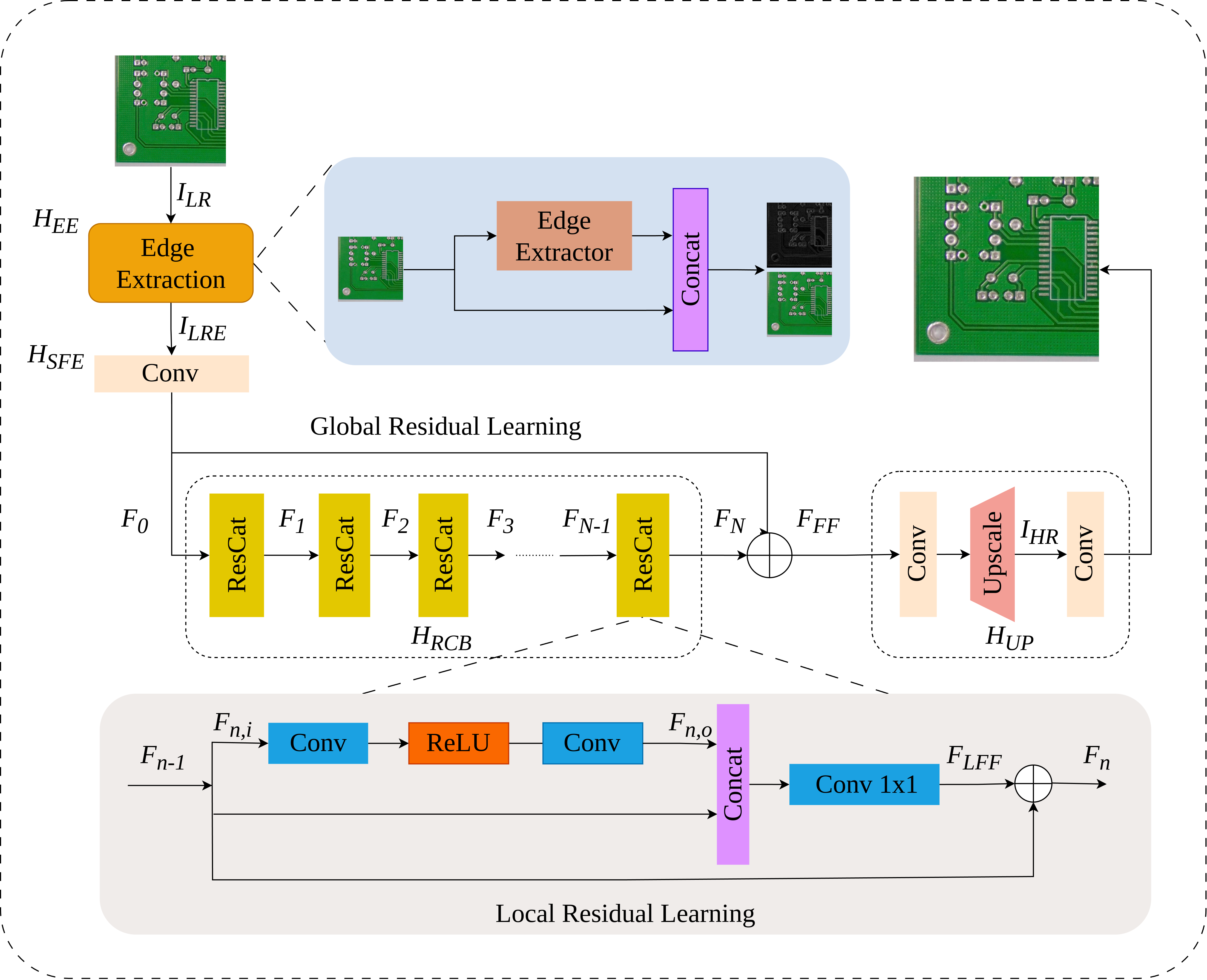
Xiem HoangVan, Thanh Nguyen Canh, Dang Bui Dinh, Van-Truong Nguyen Journal version, accepted to EAAI , 2025. <<<<<<< HEAD website / video / arxiv / code ======= website / video / arxiv / code >>>>>>> 45fca8f1f5d948b3d60119fc2fe2a8f929dd8180 Printed Circuit Boards (PCBs) are critical components in modern electron- ics, which require stringent quality control to ensure proper functionality. However, the detection of defects in small-scale PCBs images poses signif- icant challenges as a result of the low resolution of the captured images, leading to potential confusion between defects and noise. To overcome these challenges, this paper proposes a novel framework, named ESRPCB (edge- guided super-resolution for PCBs defect detection), which combines edge- guided super-resolution with ensemble learning to enhance PCBs defect de- tection. Our approach leverages the edge information to guide the EDSR (Enhanced Deep Super-Resolution) model with a novel ResCat (Residual Concatenation) structure, enabling it to reconstruct high-resolution images from small PCBs inputs. By incorporating edge features, the super-resolution process preserves critical structural details, ensuring that tiny defects remain distinguishable in the enhanced image. Following this, a multi-modal defect detection model employs ensemble learning to analyze the super-resolved image, improving the accuracy of defect identification. Experimental re- sults demonstrate that ESRPCB achieves superior performance compared to State-of-the-Art (SOTA) methods. Our model attains an average Peak Signal to Noise Ratio (PSNR) of 30.54 dB(decibel), surpassing EDSR by 0.42dB. In defect detection, ESRPCB achieves a mAP50(mean average pre- cision at an Intersection over Union threshold of 0.50) of 0.965, surpassing EDSR (0.905) and traditional super-resolution models by over 5%. Further- more, our ensemble-based detection approach further enhances performance, achieving a mAP50 of 0.977. These results highlight the effectiveness of ESRPCB in enhancing both image quality and defect detection accuracy, particularly in challenging low-resolution scenarios scenarios. |
| Projects for robot learning |
|
Thanh Nguyen Canh, Tuan Thanh Tran, Anh Viet Lam, Nak Young Chong, Xiem HoangVan Journal version, submitted to TRO , 2025. Robotic manipulation through learning from demonstration aims to enable robots to acquire various actions efficiently. Unlike traditional learning from observation-action pairs, which is time-consuming and requires proficiency in coding. Our approach is inspired by the way humans learn and imitate actions in a more flexible and efficient manner by simply "\textit{watching}" and "\textit{repeating}" the actions. Inspired by this, we propose a "Human-to-Robot" imitation learning pipeline, which enables robots to learn diverse actions from video demonstrations. Specifically, we explicitly represent each step as two key tasks: (1) understanding the demonstration video and (2) learning the demonstrated manipulations. First, the video description is achieved by focusing on two essential commonsense properties: action understanding and object understanding. We utilize deep Convolutional Neural Networks (CNNs) and Large Vision Models (VLMs) to extract meaningful features related to these properties. Then, for execution, we develop a robot manipulation system built upon a Language Vision-conditioned architectures and Deep Reinforcement Learning. Experiments with real-world video demonstrations. The results show the robustness and adaptability of the two frameworks in various scenarios using a real robotic arm UR5. |

|
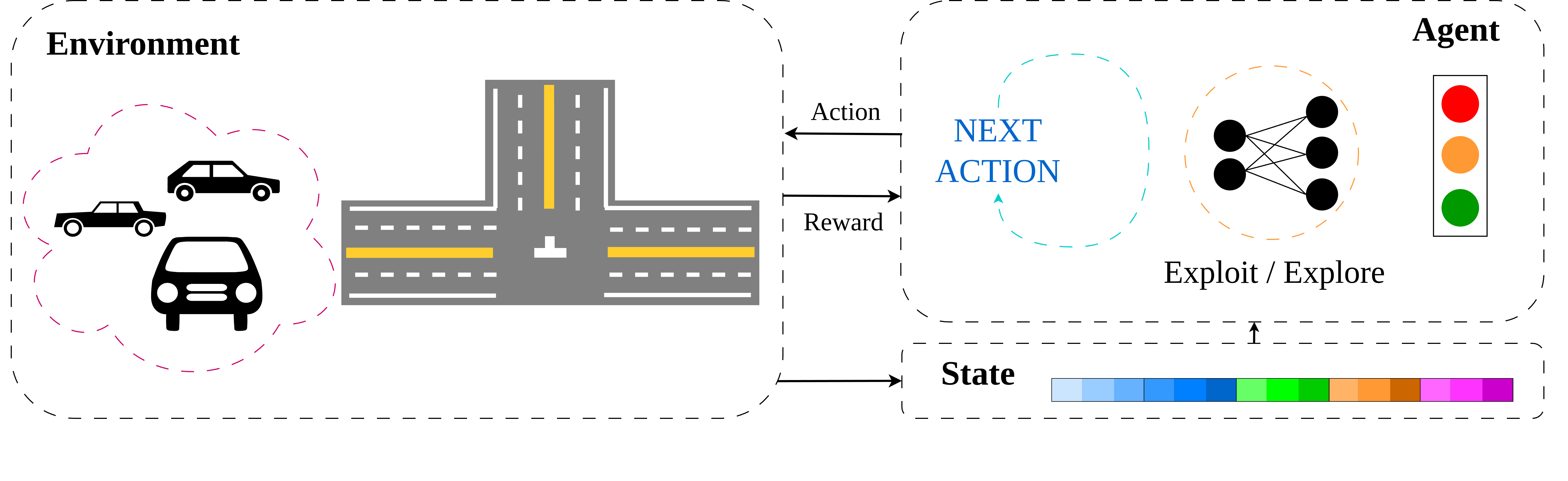
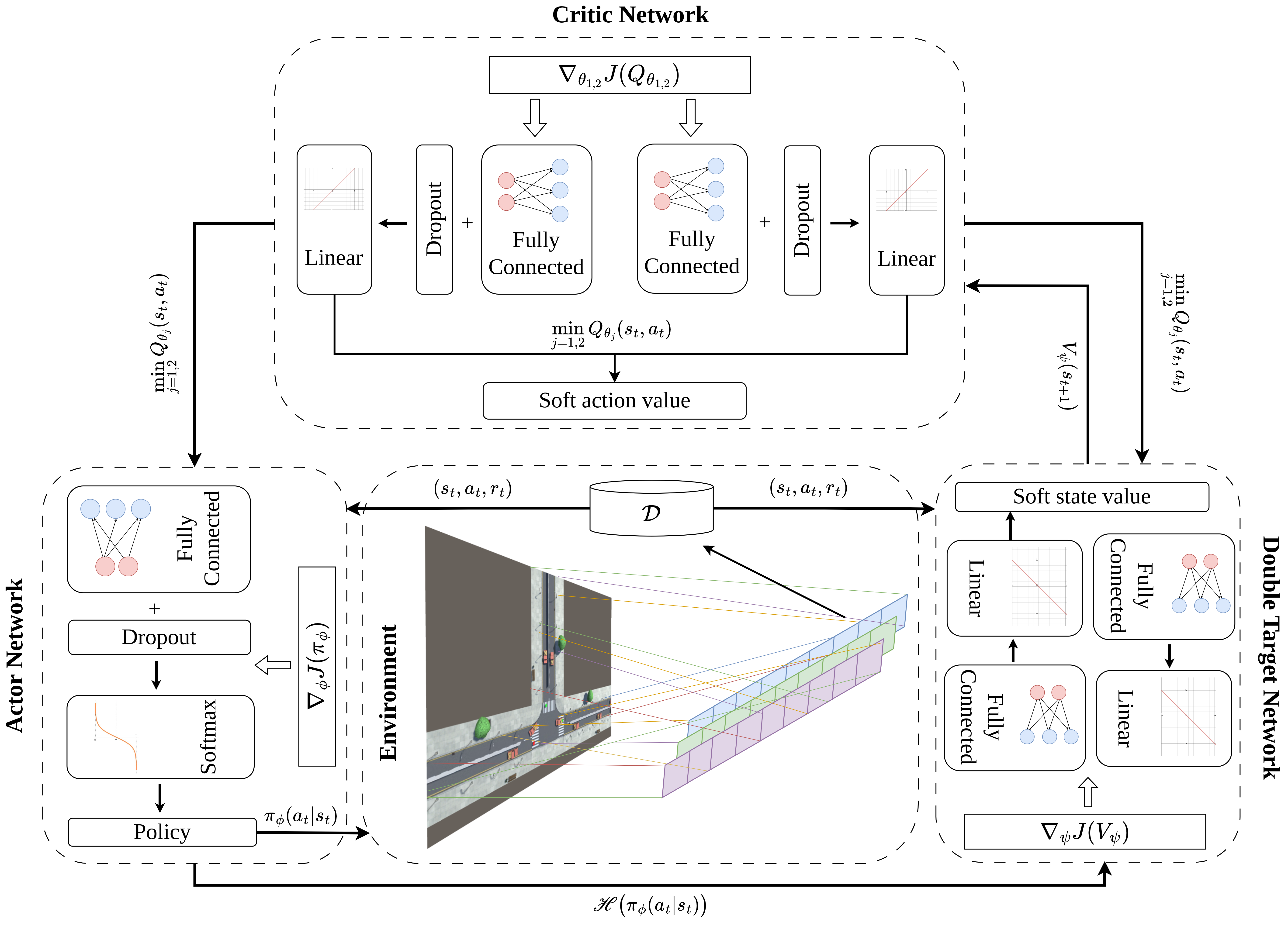
Thanh Nguyen Canh, Anh Pham Tuan, Xiem HoangVan Journal version, submitted to Public Transport , 2025. website / video / Research Square / code Traffic light control (TSC) is an important and challenging real-world problem with the aim of reducing travel time as well as saving energy. Recent researches have numerous attempts to apply intelligent methods for TSC at four-way crossroads to solve the traffic light scheduling problem. However, there is the limitation of researches on efficient TSC at three-way crossroads. Therefore, this paper introduces a novel TSC solution for three-way crossroad environment (TW-TSC). The proposed TSC method is designed based on a deep reinforcement learning approach, namely Soft Actor-Critic (TWSAC). Firstly, we create a simulation environment for three-way crossroads which consists of numerous transportation and two parallel lanes using Unity framework. Secondly, to achieve practical movements of transportation in three-way crossroads, we carefully design agents which have a high impact to the transportation movement, notably the time to wait for traffic light, the velocity of transportation, and the number of transportation passing successfully. Finally, to achieve TW-TSC efficiency, we propose a novel reward function together with a design of TWSAC algorithm. Experimental results show that the proposed TWSAC in TW-TSC achieves higher performance than both fixed-time TSC methods and relevant RL algorithms. |
|
Thanh Nguyen Canh, Son Tran Duc, Huong Nguyen The, Trang Huyen Dao, Xiem HoangVan Journal version, accepted to Engineering Science and Technology, an International Journal , 2024. website / video / Rapid advancement in robotics technology has paved the way for developing mobile service robots capable of human interaction and assistance. In this paper, we propose a comprehensive approach to design, fabricate, and optimize the overall structure of a dual-arm service robot. The conceptual design phase focuses on both critical components, the mobile platform and the manipulation system, essential for seamless navigation and effective task execution. In the proposed system, the distribution of the robot payload in terms of region, maximum stress, and displacement is examined, comprehensively analyzed, and compared with the relevant works. In addition, to enhance the system’s efficiency while minimizing its weight, we introduce a lightweight design approach in which Finite Element Analysis is utilized to optimize the frame structure. Subsequently, we fabricate a physical prototype based on the derived model. Finally, we provide a kinematic model for our dual-arm service robot and demonstrate its efficacy in both control and human–robot interaction (HRI) tasks. Experimental results indicate that the proposed dual arm design can achieve a significant weight reduction of 25% from the original design while still performing actions smoothly for HRI tasks. |
| Projects for reliable localization and safety path planing |
|
Thanh Nguyen Canh, Huy-Hoang Ngo, Xiem HoangVan, Nak Young Chong Conference version, accepted to ICCAS , 2024. website / video / arxiv / Localization is one of the most crucial tasks for Unmanned Aerial Vehicle systems (UAVs) directly impacting overall performance, which can be achieved with various sensors and applied to numerous tasks related to search and rescue operations, object tracking, construction, etc. However, due to the negative effects of challenging environments, UAVs may lose signals for localization. In this paper, we present an effective path-planning system leveraging semantic segmentation information to navigate around texture-less and problematic areas like lakes, oceans, and high-rise buildings using a monocular camera. We introduce a real-time semantic segmentation architecture and a novel keyframe decision pipeline to optimize image inputs based on pixel distribution, reducing processing time. A hierarchical planner based on the Dynamic Window Approach (DWA) algorithm, integrated with a cost map, is designed to facilitate efficient path planning. The system is implemented in a photo-realistic simulation environment using Unity, aligning with segmentation model parameters. Comprehensive qualitative and quantitative evaluations validate the effectiveness of our approach, showing significant improvements in the reliability and efficiency of UAV localization in challenging environments. |
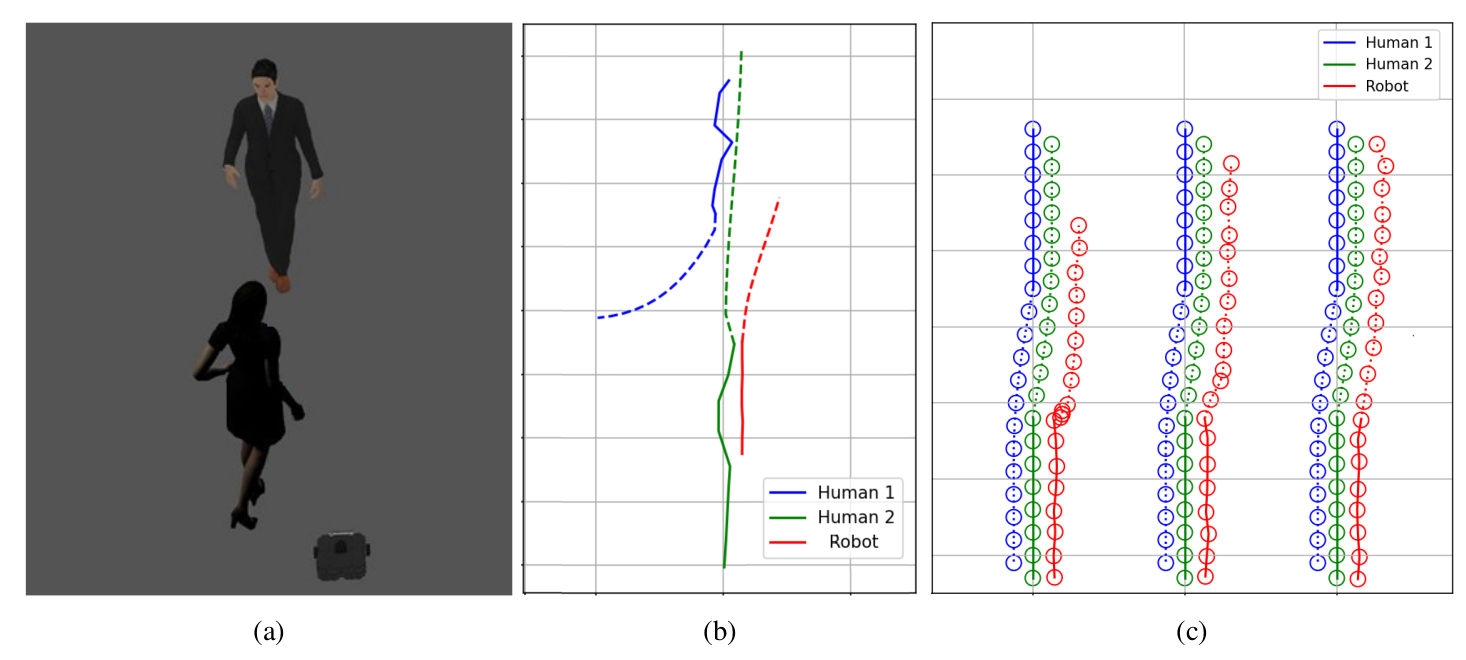 |
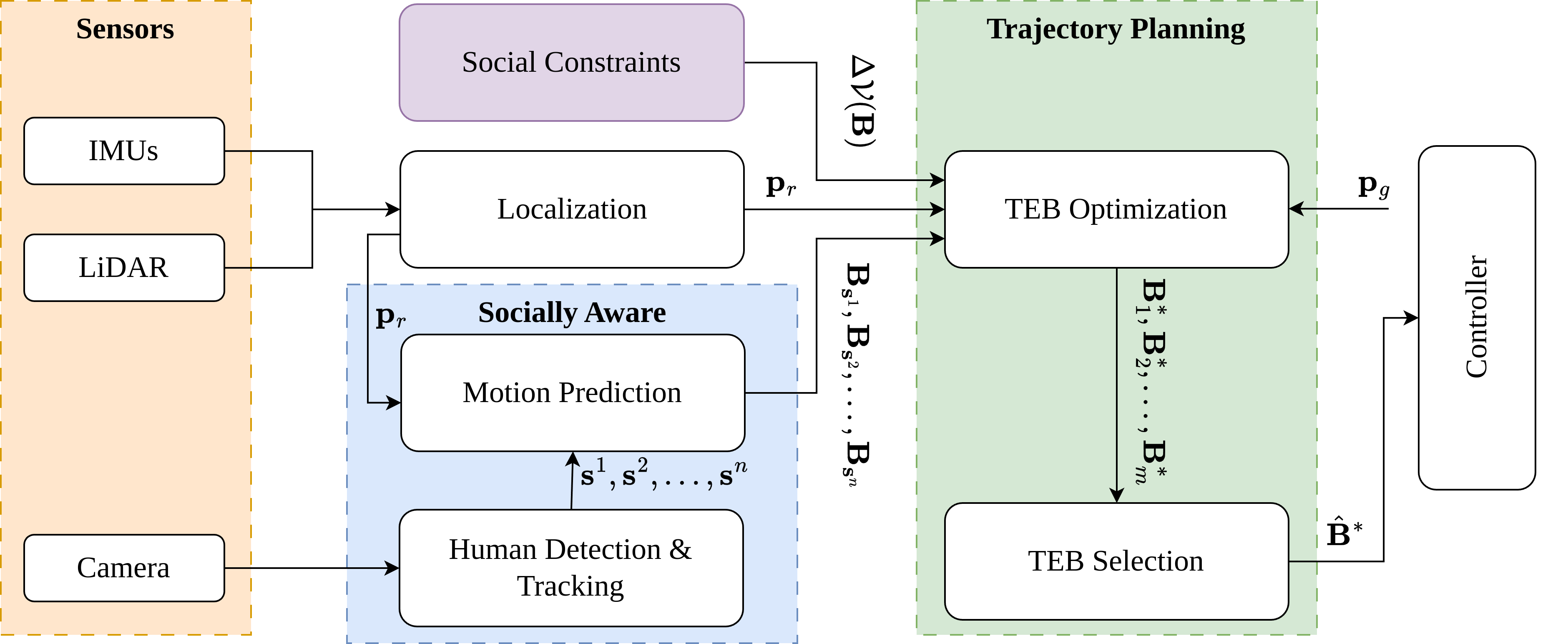
Thanh Nguyen Canh, Xiem HoangVan Nak Young Chong Conference version, accepted to ICCAS , 2024. website / video / arxiv / code Navigating safely in dynamic human environments is crucial for mobile service robots, and social navigation is a key aspect of this process. In this paper, we proposed an integrative approach that combines motion prediction and trajectory planning to enable safe and socially-aware robot navigation. The main idea of the proposed method is to leverage the advantages of Socially Acceptable trajectory prediction and Timed Elastic Band (TEB) by incorporating human interactive information including position, orientation, and motion into the objective function of the TEB algorithms. In addition, we designed social constraints to ensure the safety of robot navigation. The proposed system is evaluated through physical simulation using both quantitative and qualitative metrics, demonstrating its superior performance in avoiding human and dynamic obstacles, thereby ensuring safe navigation. |
| Projects for 3D robot calibration |
 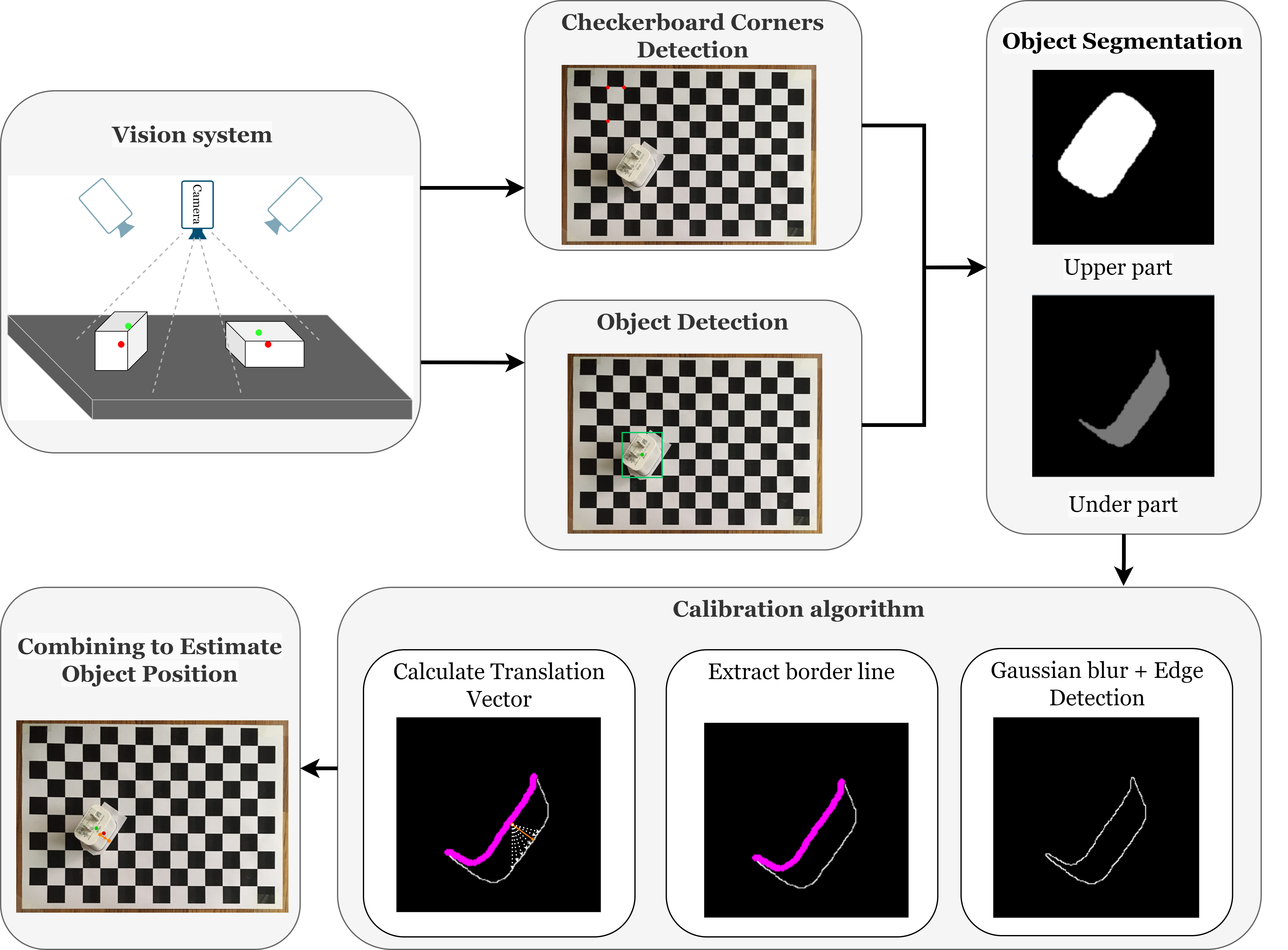
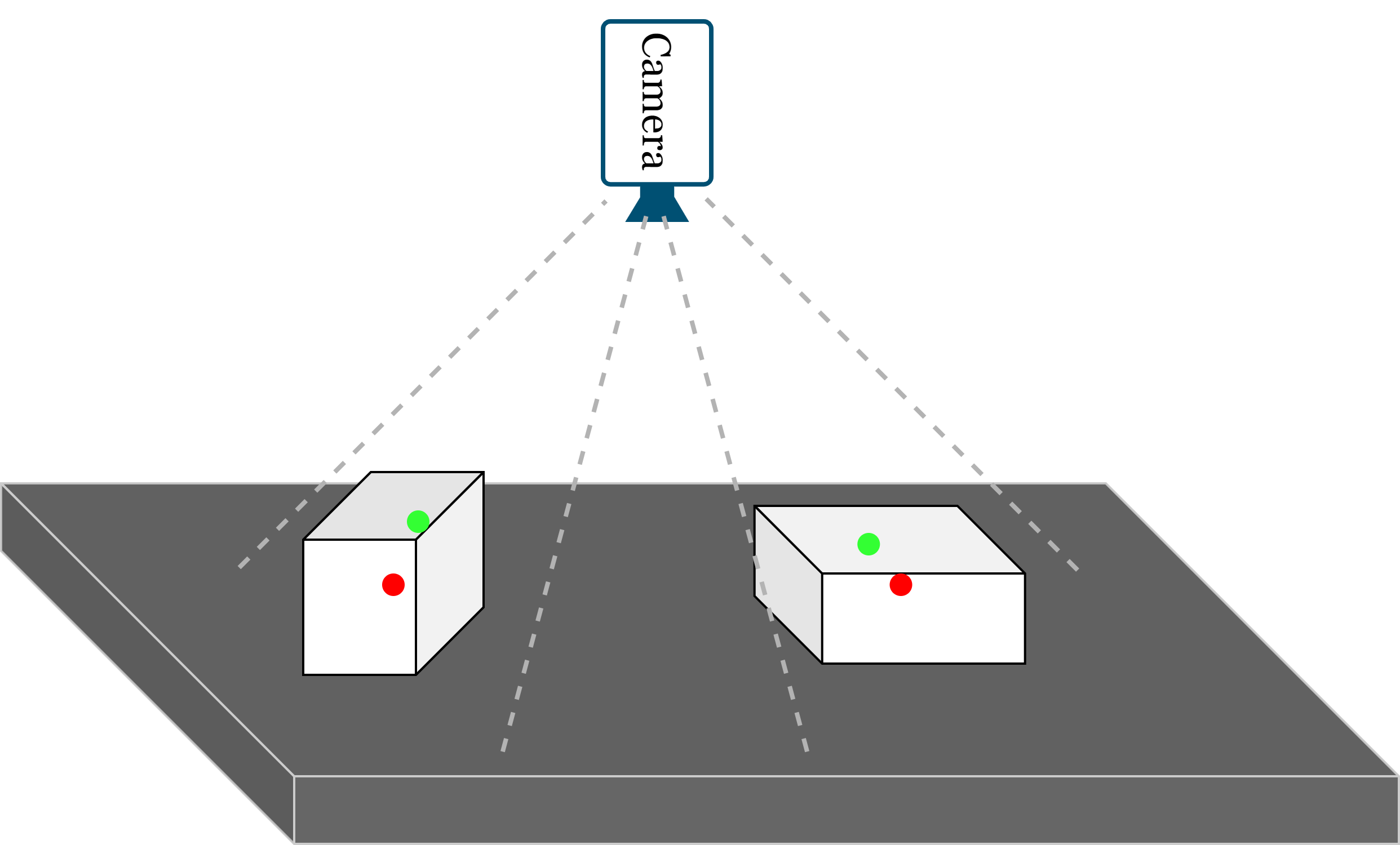
|
Thanh Nguyen Canh, Du Ngoc Trinh, Xiem HoangVan Journal version, accepted to Journal of Automation, Mobile Robotics and Intelligent Systems (JAMRIS) , 2024. website / video / Research Square / code 3D Object Localization has been emerging recently as one of the challenges of Machine Vision or Robot Vision tasks. In this paper, we proposed a novel method designed for the localization of isometric flat 3D objects, leveraging a blend of deep learning techniques primarily rooted in object detection, postimage processing algorithms, and pose estimation. Our approach involves the strategic application of 3D calibration methods tailored for low-cost industrial robotics systems, requiring only a single 2D image input. Initially, object detection is performed using the You Only Look Once (YOLO) model, followed by segmentation of the object into two distinct parts— the top face and the remainder— using the Mask R-CNN model. Subsequently, the center of the top face serves as the initialization position and a unique combination of postprocessing techniques and a novel calibration algorithm is employed to refine the object’s position. Experimental results demonstrate a notable reduction in localization error by 87.65% when compared to existing methodologies. |